Последнее обновление:
Как удалить концы строк из текста средствами РНР
Задача удаления концов строчек из (многострочной) строки текста бывает обусловлена, к примеру, когда такая строка прочитана из текстового файла. В этой статье рассмотрим, насколько эффективны различные способы такого удаления.
Символы концов строк
В операционной системе Linux конец строки обозначается символом \n (или LF), а в Windows – двумя символами: \r \n (CR LF). Обратите внимание, что слеш \ и идущая после него буква (r или n) является ОДНИМ байтом (т.е. 1 байт), хотя для его обозначения требуется ДВА текстовых символа.
Так как файл может быть записан как в Windows, так и в Linux, будем удалять, для надежности, и тот, и другой символы.
Способы удаления концов строк
Рассмотрим наиболее известные пять способов (функции) для удаления концов строк:
1. str_replace(array("\r\n", "\r", "\n"), '', $string[$i]); - для каждой из строчек (записанных в массив) по отдельности, в цикле
2. str_replace(array("\r\n", "\r", "\n"), '', $string); - из всего содержимого файла, как одной строки
3. rtrim($string); - специальная функция для удаления концов строк (а также табуляции, пробелов в конце строк)
4. preg_replace('/[\r\n]/', '', $string); - функция удаления концов строк, использующая регулярное выражение для всего содержимого файла, как одной строки
5. preg_replace('/[\r\n]/', '', $string); - функция удаления концов строк, использующая регулярное выражение для каждой из строчек (записанных в массив) по отдельности, в цикле
1. Функция str_replace
Эта функция производит замену символов концов строк везде во всей строке. Ее можно использовать как построчно (если текстовый файл был читан при помощи функции file(), которая каждую строчку записывает в соответствующий элемент массива), так и применительно к строке в целом (если файл был считан при помощи функции file_get_contents() в виде единой строки, содержащей, однако, символы \r, \n).
2. Функция rtrim()
Она предназначена СПЕЦИАЛЬНО для того, чтобы удалять концы строк (т.е. символы \r, \n) из текстовой строки. Ее можно применить, если файл был считан в построчном режиме. Тогда как, если он считан в виде единой строки – применение ее напрямую невозможно.
3. Функция preg_replace()
Эта функция производит удаление концов строк путем применения регулярного выражения. При работе с содержимым, прочитанным из файла, как с отдельной строкой, эта функция работает на порядок дольше, чем ранее обсуждавшиеся функции. А вот при обработке содержимого файла, как отдельных строк массива, эта функция показывает гораздо лучший результат. Результаты тестирования приведены ниже.
Программный код
Для тестирования различных подходов использовался следующий программный код на РНР:
<?php
$file_arr1 = file($_SERVER['DOCUMENT_ROOT'] . '/' . 'Sitemap.xml');
$file_arr2 = file($_SERVER['DOCUMENT_ROOT'] . '/' . 'Sitemap.xml');
$file_arr_len1 = sizeof($file_arr1);
$file_arr_len2 = sizeof($file_arr2);
$file_arr11 = array();
$file_arr22 = array();for($j=0; $j<20; $j++) {
$t = microtime();
for ($i = 0; $i < $file_arr_len1; $i++) {
$file_arr11[$i] = str_replace(array("\r\n", "\r", "\n"), '', $file_arr1[$i]);
}
$t1 = microtime();
$time1[$j] = $t1 - $t; for ($i = 0; $i < $file_arr_len2; $i++) {
$file_arr22[$i] = rtrim($file_arr2[$i]);
}
$t2 = microtime();
$time2[$j] = $t2 - $t1; echo 'time1 (str_replace)=' . $time1[$j] . ' ' . 'time2 (rtrim)=' . $time2[$j] . '<br/>';
}
//echo implode('', $file_arr1) .'<br/><br/>';
//echo implode('', $file_arr2) .'<br/><br/>';$time1_all=0;
$time2_all=0;
for($j=0; $j<20; $j++) {
$time1_all += $time1[$j];
$time2_all += $time2[$j];
}
$time1_all = $time1_all/sizeof($time1);
$time2_all = $time2_all/sizeof($time2);$str = file_get_contents($_SERVER['DOCUMENT_ROOT'] . '/' . 'Sitemap.xml');
$t = microtime();
for($j=0; $j<20; $j++) {
$t1 = microtime();
$file_arr = str_replace(array("\r\n", "\r", "\n"), '', $str);
$time3[$j] = $t1 - $t;
$str = file_get_contents($_SERVER['DOCUMENT_ROOT'] . '/' . 'Sitemap.xml');
}
//echo $file_arr;
$time3_all=0;
for($j=0; $j<20; $j++) {
$time3_all += $time3[$j];
}
$time3_all = $time3_all/sizeof($time3);$str = file_get_contents($_SERVER['DOCUMENT_ROOT'] . '/' . 'Sitemap.xml');
$t = microtime();
for($j=0; $j<20; $j++) {
$t1 = microtime();
$file_arr = preg_replace('/[\r\n]/', '', $str);
$time4[$j] = $t1 - $t;
$str = file_get_contents($_SERVER['DOCUMENT_ROOT'] . '/' . 'Sitemap.xml');
}
$time4_all=0;
for($j=0; $j<20; $j++) {
$time4_all += $time4[$j];
}
$time4_all = $time4_all/sizeof($time4);$file_arr5 = file($_SERVER['DOCUMENT_ROOT'] . '/' . 'Sitemap.xml');
$file_arr_len5 = sizeof($file_arr5);
for($j=0; $j<20; $j++) {
$t = microtime();
for ($i = 0; $i < $file_arr_len5; $i++) {
$file_arr = preg_replace('/[\r\n]/', '', $file_arr5[$i]);
}
$t1 = microtime();
$time5[$j] = $t1 - $t;
}
$time5_all=0;
for($j=0; $j<20; $j++) {
$time5_all += $time5[$j];
}
$time5_all = $time5_all/sizeof($time5);echo '<br/>time1_all (array, str_replace)='.$time1_all.' '.'<br/>time2_all (array, rtrim)='.$time2_all.' '.'<br/>time3_all (string, str_replace)='.$time3_all . ' <br/>time4_all (string, preg_replace)='.$time4_all. '<br/>time5_all (array, preg_replace)='.$time5_all ;
?>
Как видно, этот код последовательно удаляет концы строк из содержимого, считанного из файла. Для примера, взят файл карты сайта Sitemap.xml, находящийся в корневом каталоге сайта. Этот файл имел размер 59,7 кБ, содержал 2250 строчек.
Каждый из четырех способов удаления концов строк, для статистики, применяется 20 раз. Затем результаты усредняются. И вот что получилось:
time1_all (array, str_replace)=0.0055
time2_all (array, rtrim)=0.0027
time3_all (string, str_replace)=0.0021
time4_all (string, preg_replace)=0.0235
time5_all (array, preg_replace)=0.0064
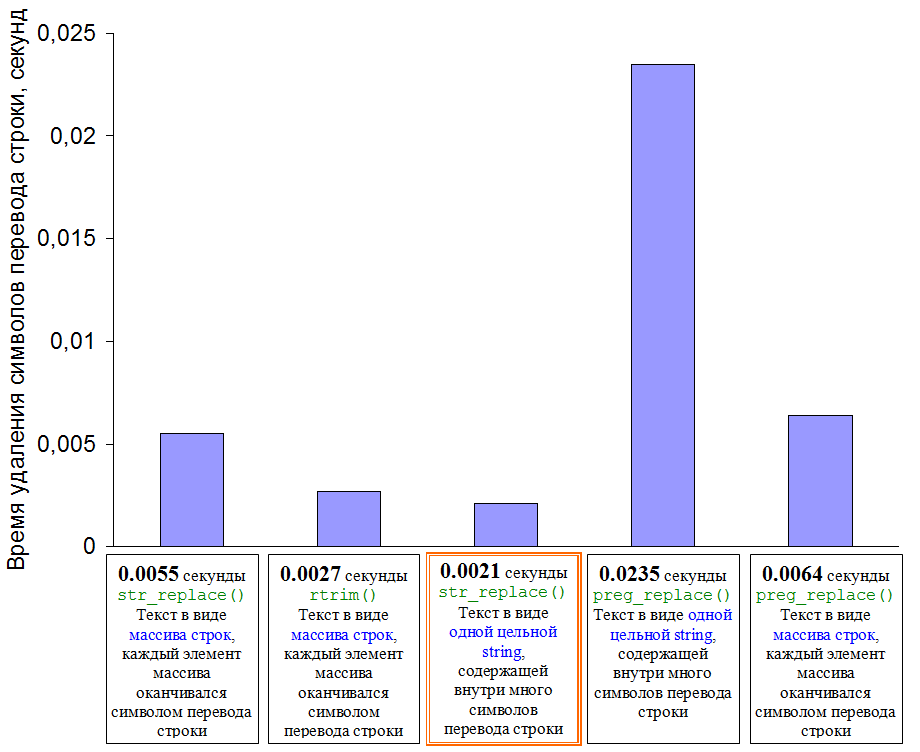
Самым быстрым оказался, как ни странно, третий способ. Это когда файл был прочитан в строку при помощи функции file_get_contents(), а затем концы строчек, содержащиеся в ней, были удалены при помощи str_replace.
Немного медленнее работает функция rtrim(), примененная к содержимому файла, считанного в массив (состоящий из отдельных строчек) и уже из его элементов, в цикле, удалялись концы строчек. По-видимому, несколько более медленная работа функции rtrim(), в данном случае, связана с массивом. А он имел не очень малый размер - состоял из 2250 элементов.
Тогда как в аналогичном цикле, функция str_replace() показала в 2 раза более медленный результат.
Ну, а что касается регулярного выражения, примененного к содержимому файла в целом, тут даже и говорить не приходится: время выполнения увеличилось на порядок! Хотя, при разбиении файла на строчки и создании соответствующего массива, функция preg_replace() работает быстрее. Но, даже и в этом случае – чисто строковые функции (без регулярных выражений) работают быстрее.
Выводы
Итак, наверное, банально, но, все же, стоит отметить:
- Для функции
str_replace()использование массивов, по сравнению с единой, цельной строкой (string) немного замедляет выполнение программ на РНР (по крайней мере, на примере удаления концов строк); при этом дело не касается использования регулярных выражений.
Тогда как при использовании регулярных выражений (функцияpreg_replace()), напротив, предпочтительнее использовать массивы… чтобы снизить размер единовременно обрабатываемой строки. - По возможности, следует использовать готовые, специально предназначенные для конкретной задачи, функции, которые, при прочих одинаковых условиях, работают быстрее, чем те, что являются более универсальными. Так, при обработке массива из строчек функция
rtrim()работала в 2 раза быстрее, чем аналогичная, но более универсальная функцияstr_replace(). Использование специально предназначенной для этого функцииrtrim()в данном случае – более скоростной вариант. - Однако, если читать файл в одну, цельную строку и удалять символы переноса строк из нее, то, все же, функция
str_replace()работает немного БЫСТРЕЕ, чемrtrim(). Оказалось, что это - наиболее скоростной вариант среди пяти тестировавшихся. - Регулярное выражение, даже очень простой конструкции, работает гораздо медленнее «обычных» строковых функций, особенно, при обработке больших строк. А что будет при мало-мальски серьезном регулярном выражении?... Поэтому регулярные выражения если и следует применять, то лишь там, где производительность НЕ ЯВЛЯЕТСЯ критичной. Да, очень хороши и полезны регулярные выражения, например, при проверке правильности заполнения полей форм, при проверке адресов URL или e-mail. Но, использовать их для больших строк, как видится, нецелесообразно.
- Если разбить строку на подстроки (в виде массива), то обработка при помощи регулярных выражений будет происходить гораздо БЫСТРЕЕ.
Обобщение
Отметим, что данные выводы, скорее всего, справедливы не только для языка PHP, но и для многих других аналогичных языков, например, Python, C#, Ruby. Т.е. для высокоуровневых языков. Потому, что в этих языках команды, по сути, представляют собой, всего-навсего, набор готовых скриптов той или иной степени эффективности. Написанных на языке С/С++.
Поэтому целесообразнее применять именно ту функцию, которая как раз и предназначена для выполнения соответствующей задачи, взамен более универсальной функции. Правда, из этого правила бывают исключения. Как видим, в третьем варианте универсальная функция str_replace() сработала, все-таки, быстрее специализированной rtrim(). Кстати, такой же парадокс наблюдается и для специализированной функции file(): она работает, как ни странно, раза в 2 медленнее, чем пара функций fopen() + explode().
А вот для программ на С/С++ - разница, видимо, будет не столь заметна.
Что касается регулярных выражений, то, как видно, чем меньше размер строки (на каждой итерации цикла), тем быстрее происходит обработка. По результатам тестирования получилось, что разбиение содержимого, считанного из файла, в массив (построчно) показало гораздо более лучший (в смысле быстроты обработки) результат, по сравнению с обработкой содержимого файла как одной цельной строки (тогда как при использовании str_replace() - все полностью наоборот). При этом, что интересно, время работы функции preg_replace() ненамного выше, чем время работы функции str_replace(), хотя последняя, вроде как, работает с «чистыми» строками, без использования регулярных выражений.
В целом же, можно сделать такой вывод
. Не стоит использовать первую попавшуюся функцию в РНР только потому, что она присутствует в этом языке и кем-то рекомендована. Если, конечно, вебразработчика интересует быстрота работы программы на PHP, равно как и скорость открытия страниц сайта в целом. Если в конкретной ситуации язык дает несколько возможностей для решения одной и той же задачи (т.е. если возможно применить разные функции), то, чтобы сайт функционировал наиболее быстро, следует, увы, тестировать, как работает каждая из функций и выбирать наиболее оптимальную. Да, вывод этот, конечно, банальный. Однако, скорость работы функций РНР в маннуалах не прописана. Да и на форумах компьютерных этот вопрос, зачастую, как-то обходят стороной. Работает мол (как-то там), да и ладно. Так что выход здесь один: практическое тестирование функциональности/скорости. Не обращая внимания на маннуалы.
Понятно, что для небольших сайтов, при обработке сравнительно небольших строк, слабой нагруженности сайта, в самом деле, нет смысла что-то там оптимизировать и вылавливать эти доли секунд. В самом деле, какая разница - выполнится некая операция то ли за 0,002 секунды, то ли за 0,02 секунды? Все равно, мол, очень быстро. Но, по мере развития сайта, по мере роста посещаемости - все эти, казалось бы, мелочи, в итоге, сложившись, могут дать существенное замедление скорости работы сайта. И, как следствие - падение позиций в поисковиках, появление определенных, не особенно приятных, чувств к такому сайту у пользователей. Кто-то в подобной ситуации может начать думать в направлении, мол, более мощного сервера. А лучше бы, в первую очередь, выбирать оптимальные, для каждого случая, функции.
Правда, озвученный выше подход, скорее всего, ОЧЕНЬ не понравится так называемым любителям "командной работы". Ну, это когда "команда" состоит из (бывших) студентов-троечников, каждый из которых является, так сказать, "узким специалистом" (ну, т.е. таким, который освоил лишь что-то одно, да и то - на минимальном уровне). И/или когда принцип работы "команды" - примерно такой: программистам - определенная зарплата (ну, быть может, плюс некие премии), а руководству - все остальные финансы и доходы.