Последнее обновление:
PHP & C
Для целей тестирования были использованы два языка: РНР и С. Задача, которую выполняли программы, написанные на этих языках:
Читать с жесткого диска большой текстовый файл, сравнивать каждую из его строк с наперед заданной строкой (сохранявшей постоянное значение).
Характеристика файла:Размер: 6,1 МБЧисло строк: до 429963 (т.е. 400 тыс. с лишним строк)Размер каждой из строк: от 9 до 12 символовВиды символов: цифры от 0 до 9 и точки
На самом деле, этот файл представлял содержал в себе совокупность локальных IP-адресов, многие из которых имели неправильные значения в последнем разряде. Вот начало этого файла:
и его конец:
Строки периодически повторялись.
Задача обработки подобных файлов часто встречается в работе вебсерверов. Например, сравнить текущий IP-адрес с тем, который имеется в базе файле данных требуется, чтобы определить, разрешен ли доступ к серверу с соответствующего адреса (т.е. не забанен ли он). Или, к примеру, в зависимости от вида IP-адреса пользователя – предоставить ему с сервера тот или иной вид вебстраницы.
Впрочем, вместо адресов вполне могут фигурировать и иные данные, например – аутенификационные данные пользователей (да, обычно все такое хранится в базах данных, но в данный момент речь не о них).
Язык РНР
На языке PHP написаны три программы, которые различаются технологией работы с файлами (как мы увидим ниже, по скорости обработки файла они – немного разные). На языке С использовалось полторы программы (см. ниже). Программы запускались в среде виртуального сервера Denwer, в операционной системе Windows 7.
Технология работы программ на PHP
Для PHP использовалось три известных технологии открытия файла:
При помощи функций
fopen+explodeПри помощи функции
fileПри помощи функций
fopen+fgets
Возможно, язык РНР содержит в себе еще и какие иные возможности для указанной цели, но в рамках данной статьи ограничимся тремя вышеозвученными.
Ниже приведены тексты (коды) программ на РНР. Рассмотрим кратко их суть и особенности.
1. Функции fopen+explode
Текстовый файл открывается при помощи функции fopen, считывается полностью, затем при помощи функции explode из него вырезаются концы строк (символы \n) и одновременно его содержимое преобразуется в массив, число элементов которого равно число строк текстового файла, соответственно.
Далее, заданная строка, имеющая вид 127.0.01А, поочередно сравнивается с каждым из элементов полученного массива.
Примечание: буква «А» добавлена специально, чтобы при сравнении не были выявлены одинаковые строки (например, стр. 3, 6 текстового файла, см. рисунок выше).
Для контроля времени, непосредственно до процедуры обработки файла запускался счетчик времени, который останавливался сразу после окончания обработки. Тем самым, выводилась информация о потраченном времени на работу программы.
2. Функция file
Эта функция считывает весь текстовый файл целиком, передает его в массив (по аналогии с функциями fopen+explode). Затем производилось сравнение каждого из элемента полученного массива (из которого предварительно вырезались символы концов строк) с указанной выше строкой 127.0.01А.
3. Функции fopen+fgets
При использовании этих функций – файл также открывался, затем данные считывались из него ПОСТРОЧНО (тогда как в предыдущих двух способах файл читался целиком). Далее, каждая строка (предварительно из нее вырезались символы концов строк) сравнивалась со строкой 127.0.01А.
Код программ на PHP
Ниже приведен текст (код) программ на РНР:
<?php
$ip3= "?";
//IP-адрес пользователя
$ip = $_SERVER['REMOTE_ADDR'];
// При помощи fopen+explode:
$time1 = microtime(true);
$input = fopen($fname = $_SERVER['DOCUMENT_ROOT'].'/ip_tmp.txt', "rt");
$fname = explode("\n", fread($input, filesize($fname)));
$fname_length = count($fname);
for($i=0; $i<$fname_length-1; $i++){
if($ip."A" === $fname[$i]) {
$ip3 = 1; break;
}
}
fclose($input);
unset($fname);
$time1 = microtime(true)-$time1;
echo "fopen+explode: ".$time1."<br/>";
// При помощи file:
$time2 = microtime(true);
$input = @file($_SERVER['DOCUMENT_ROOT'].'/ip_tmp.txt');
$input_length = count($input);
for($i=0; $i<$input_length-1; $i++){
if($ip."A" === trim($input[$i])) {
$ip3 = 2; break;
}
}
unset($input);
$time2 = microtime(true)-$time2;
echo "file: ".$time2."<br/>";
// При помощи fopen+fgets:
$time3 = microtime(true);
$input = @fopen($_SERVER['DOCUMENT_ROOT'].'/ip_tmp.txt', "r");
for($i=0; $i<$input_length-1; $i++){
$buffer = fgets($input);
if($ip."A" === trim($buffer)) {
$ip3 = 3; break;
}
}
fclose($input);
unset($buffer);
$time3 = microtime(true)-$time3;
echo "fopen+fgets: ".$time3."<br/>";
// Записываем данные в файл
$input = @fopen($_SERVER['DOCUMENT_ROOT'].'/ip_tmp_data-encrease__.csv', "a+");
$input_arr = array($time1, $time2, $time3, $input_length);
fputcsv($input, $input_arr, ';');
fclose($input);
// Дописываем данные в файл, т.е. увеличиваем количество строк
$input = @fopen($_SERVER['DOCUMENT_ROOT'].'/ip_tmp.txt', "a");
for($i=1; $i<10000; $i++)
fputs($input, PHP_EOL.$ip.$i);
fclose($input);
// Строим таблицу значений
$input = @fopen($_SERVER['DOCUMENT_ROOT'].'/ip_tmp_data-encrease__.csv', "r");
echo "<table border='1px solid' style='width: 800px'><tbody>";
echo "<tr><td>"."fopen+explode: "."</td><td>"."file: "."</td><td>"."fopen+fgets: "."</td><td>".mb_convert_encoding("Число строк в файле:", Encoding_rus_letters, "utf-8" )."</td></tr>\n";
while (($buffer = fgetcsv($input, 1000, ";")) !== false) {
echo "<tr><td>".$buffer[0]."</td><td>".$buffer[1]."</td><td>".$buffer[2]."</td><td>".$buffer[3]."</td></tr>\n";
}
fclose($input);
echo "</tbody></table>";
die("ip3=".$ip3);?>
Для целей преемственности результатов, расчеты проводились, начиная с текстового файла небольшого размера, содержащего всего несколько строк. Затем, после обработки файла их количество увеличивалось на 10000 и расчеты повторялись заново. Результаты последних расчетов представлены ниже в таблице:
| Время, затраченное на просмотр и обработку всех строк файла, секунды | Число строк в файле, тыс. шт. | ||
| fopen+explode: | file: | fopen+fgets: | |
| 0,077 | 0,126 | 0,179 | 109,995 |
| 0,072 | 0,136 | 0,191 | 119,994 |
| 0,084 | 0,146 | 0,216 | 129,993 |
| 0,107 | 0,164 | 0,232 | 139,992 |
| 0,091 | 0,172 | 0,243 | 149,991 |
| 0,094 | 0,186 | 0,263 | 159,990 |
| 0,093 | 0,197 | 0,279 | 169,989 |
| 0,128 | 0,206 | 0,293 | 179,988 |
| 0,125 | 0,216 | 0,310 | 189,987 |
| 0,117 | 0,231 | 0,325 | 199,986 |
| 0,116 | 0,242 | 0,345 | 209,985 |
| 0,114 | 0,256 | 0,356 | 219,984 |
| 0,129 | 0,260 | 0,370 | 229,983 |
| 0,168 | 0,278 | 0,383 | 239,982 |
| 0,133 | 0,281 | 0,401 | 249,981 |
| 0,161 | 0,295 | 0,420 | 259,980 |
| 0,184 | 0,310 | 0,433 | 269,979 |
| 0,173 | 0,321 | 0,450 | 279,978 |
| 0,170 | 0,332 | 0,469 | 289,977 |
| 0,165 | 0,342 | 0,484 | 299,976 |
| 0,173 | 0,361 | 0,501 | 309,975 |
| 0,177 | 0,371 | 0,513 | 319,974 |
| 0,194 | 0,379 | 0,532 | 329,973 |
| 0,181 | 0,390 | 0,547 | 339,972 |
| 0,191 | 0,397 | 0,560 | 349,971 |
| 0,201 | 0,407 | 0,582 | 359,970 |
| 0,196 | 0,420 | 0,596 | 369,969 |
| 0,231 | 0,429 | 0,613 | 379,968 |
| 0,232 | 0,457 | 0,629 | 389,967 |
| 0,214 | 0,457 | 0,643 | 399,966 |
| 0,257 | 0,464 | 0,658 | 409,965 |
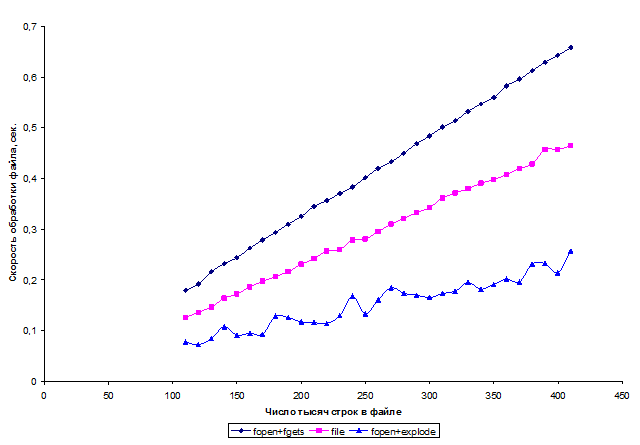
Для наглядности, данные таблицы отложены на графике:
Выводы
Итак, что видим? Самым быстрым методом является первый, т.е. тот, который использует функции fopen+explode. Как ни странно, функция file (ОДНА вместо ДВУХ указанных) работает… медленнее в 1,8 раза.
Поэтому, как видится, в настоящее время функция file в PHP попросту не нужна. Поэтому в дальнейшем разговор о ней опустим.
Самый длительный способ – при построчном считывании и обработке файла, т.е. с использованием функций fopen+fgets. Он примерно в 2,5 раза более длителен по сравнению с первым способом. Поэтому третий способ следует применять лишь тогда, когда необходимо просмотреть и/или обработать лишь небольшую часть строк файла.
Однако, чем выгоднее третий способ – построчной обработки? Конечно же, малой потребностью в оперативной памяти. В самом деле, в первом способе осуществляется загрузка файла целиком. Если файл будет большой, соответственно, и время его загрузки в оперативную память будет также сравнительно большим.
Тогда как в рамках третьего способа осуществляется построчный просмотр, т.е. за каждую итерацию цикла загружается одна строка, т.е. 9…12 байт. Впрочем, скорее всего, операционная система, в целях опережающего кэширования, сама подгрузит дополнительно какое-то количество строк файла, в надежде на то, что они понадобятся в ближайшем будущем. Однако, по крайней мере, насильно ее к этому третий способ не вынуждает. Поэтому, при нехватке оперативной памяти третий способ вполне имеет право на существование. Если же последней достаточно, то наиболее целесообразнее, конечно же, первый из рассмотренных способов, т.е. обработка файла в РНР при помощи пары функций fopen+explode.
А как это работает на хостинге?
Для сравнения, приведем данные, как все это работает на одном из хостингов в сети интернет. Не хотелось повторять промежуточные расчеты, поэтому сразу приведем данные для файла с максимальным количеством строк.
С использованием языка РНР:
| Время, затраченное на просмотр и обработку всех строк файла, секунды | Число строк в файле, тыс. шт. | Где проходило тестирование | ||
| fopen+explode: | file: | fopen+fgets: | ||
| 0,257 | 0,464 | 0,658 | 409,965 | Виртуальный сервер Denver |
| 0,290 | 0,380 | 0,376 | 409,965 | Типичный хостинг в сети интернет |
Данные, однако, любопытные. Несмотря на то, что все равно первый метод (при помощи функций fopen+explode) работает быстрее, чем два остальных, тем не менее, именно он почему-то(?) работал медленнее, чем на локальном компьютере (в среде виртуального сервера Denwer). Тогда как два других, напротив, сработали быстрее. Парадокс, однако.
Который, скорее всего, обусловлен тем, что обработка файла при помощи первого метода выполнялась в первую очередь. А у сервера «дел много», хотя и он, очевидно, гораздо мощнее, чем локальный компьютер. Но, коль скоро уж он (сервер) «взялся» за работу с конкретной программой, дальше уделяет ей немного больше внимания. Поэтому оставшиеся два метода (программный код по которым идет непосредственно ниже первого, в одном и том же программном модуле) выполняются уже быстрее, чем на локальном компьютере.
В целом же, следует сказать, что даже первый метод (на основе функций fopen+explode) не подойдет в данном случае, если, скажем, файл будет занимать объем не 6,4 МБ, а раз в 10…1000 больше. Например, если предположить, что зависимость времени обработки файла от его объема останется той же самой, то получим, что, скажем, для размера файла (представляющего собой, к примеру, файловый аналог базы данных), равного 640 МБ («средний» размер файла базы данных для сайта более-менее высокой посещаемости, будет содержать немногим более 40 миллионов строк указанного в начале статьи размера) среднее время обработки составит примерно 29 секунд… впрочем, 40 млн. строк – величина тоже немалая. Далеко не всякий современный сайт сможет похвастаться подобным объемом.
А, по сути, оно будет даже больше, если иметь дело с виртуальным хостингом, на котором работают несколько сайтов. Ведь сервер не может позволить ОДНОМУ сайта такую роскошь, как непрерывную работу в течение 29 секунд (почти полминуты). Понятно, что он будет постоянно прерываться для того, чтобы обеспечить работу и других сайтов – тоже.
Впрочем, в определенные выше 0,29 секунд, наверняка, входит также и то время, в течение которого сервер, быть может, работал не только с приведенной выше программой, но также и с другими сайтами.
Что, конечно же, ОЧЕНЬ много. Если этот файл будет связан с информацией о пользователях и/или о товарах, которые часто востребованы, то пользователям будет казаться, что сайт постоянно «зависает». Не говоря уже о том, что подобных файлов может быть, вообще говоря, несколько.
Поэтому при подобных объемах файлов (а то и более высоких), если они более-менее часто необходимы для работы сайта – придется либо искать более быстрый хостинг, либо, как вариант – перейти с PHP на более скоростной язык программирования. Одним из них является С.
Правда, отметим, при таких объемах данных, скорее всего, придется вести речь уже о выделенном сервере, быть может, даже и не одном. Ведь если у сайта только файл с данными (аналог базы данных) занимает сотни мегабайт, то… каков же тогда объем его контента (статей, картинок, видео и т.п.)?...
Тогда как для, скажем так, малых и «средних» сайтов использование РНР видится вполне приемлемым. Если, конечно, технология работы сайта не предусматривает постоянного обращения к файлам с данными.
Язык С
Теперь интересно будет сравнить, как обстоит дело с другими языками. Например, протестируем язык С. Для запуска программ использовалась операционная система Linux (Ubuntu), запущенная в виде гостевой системы в среде виртуальной машины VMware Player.
Сразу приведем исходный текст (код) программы. Работает она при помощи функций fopen+fgets, как и программа в третьем способе для PHP. Понятно, что в отличие от PHP, здесь пришлось вручную выделять память; использовались типичные «сишные» функции типа strcspn, ну, и т.д.
// При помощи fopen+fgets:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <time.h>
#include <malloc.h>
int main()
{
FILE *fp;
size_t fname1_len;int i, ip3;
char ip[] = "127.0.0.1", fname[126], *fname1, *ipchar ;
ip3 = 0; i=0;
//Структуры для сохранения определенного времени
struct timespec mt1, mt2;
//Переменная для расчета дельты времени
long int tt; float tt1;
//Определяем текущее время
clock_gettime (CLOCK_REALTIME, &mt1);
fname1 = malloc(sizeof(char)*126);
ipchar = strcat(ip,"A");
fp = fopen("ip_tmp.txt", "r");
while(!feof (fp)) {
if (fgets(fname, 126, fp)) {
//Удаляем из fname разделители строк
fname1_len = strcspn(fname, "\n\r");
memset (fname1, 0, fname1_len+1);
memcpy(fname1, fname, fname1_len);
if(strcmp(ipchar, fname1) == 0) {ip3 = 1; break;}
i++;
}
}
free(fname1);
printf("ip3= %d%s%d\n", ip3, " i=", i);
//Определяем текущее время
clock_gettime (CLOCK_REALTIME, &mt2);
//Рассчитываем разницу времени между двумя измерениями
tt=((mt2.tv_sec - mt1.tv_sec)+(mt2.tv_nsec - mt1.tv_nsec));
tt1 = tt;
tt1 = tt1/1000000000;
//Выводим результат расчета времени работы программы на экран
printf ("Затрачено времени: %.5f с\n",tt1);
}
Исследование скорости выполнения указанной выше задачи (сравнить каждую строку файла с некоторым, наперед заданным строковым значением) проводилось только для максимального размера файла (т.е. для файла содержащего 429963 строки). Типичные значения времени, затраченного на выполнение указанного действия (см. приведенный выше программный код) составили:
0,052 с … 0,069 с.
Т.е. максимальное время составило 0,069 с, что примерно в 10 раз ниже, чем для аналогичной программы на РНР. Впрочем, если принимать во внимание, что программу на РНР можно оптимизировать, т.е. ускорить, то минимальное время обработки указанного файла (при его максимальном размере, равном 6,1 МБ) будет составлять примерно 0,26 сек.
Тогда как способ оптимизации программы на С (см. ниже) на неизвестен…
// При помощи fopen+fread:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <time.h>
#include <sys/time.h>
#include <malloc.h>
int main()
{
FILE *fp;
size_t fname1_len;
int i, ip3, gg, result;
char ip[] = "127.0.0.1", fname[126], *fname1, *ipchar ;
float tm_f;
ip3 = 0; i=0;
// Функция для определения времени
inline long long gettimeus()
{
struct timeval tv;
gettimeofday( &tv, NULL );
return (long long) tv.tv_sec * 1000000LL + (long long) tv.tv_usec;
}
long long tm = -gettimeus();
fname1 = malloc(sizeof(char)*126);
ipchar = strcat(ip,"A");
fp = fopen("ip_tmp.txt", "r");
while(!feof (fp)) {
if (fgets(fname, 126, fp)) {
fname1_len = strcspn(fname, "\n\r");
memset (fname1, 0, fname1_len+1);
memcpy(fname1, fname, fname1_len);
if(strcmp(ipchar, fname1) == 0) {ip3 = 1; break;}
i++;
}
}
free(fname1);
fclose(fp);
printf("ip3= %d%s%llu\n", ip3, " i=", tm);
//Определяем текущее время
tm += gettimeus();
//Рассчитываем разницу времени между двумя измерениями
//Выводим результат расчета на экран
tm_f = tm;
tm_f = tm_f/1000000;
printf ("Затрачено время: %.5f\n", tm_f);
}
Кстати, вот здесь приведена кроссплатформенная (как для Windows, так и для Linux) функция для определения времени работы программы. Вышеприведенный код использует ее.
Данная программа написана на языке С под операционную систему Linux (почему-то нелюбимую немалым количеством студентов-программистов, считающих, что он, якобы, не пригодится для профессиональной деятельности). В Windows она, естественно, не запустится (если не использовать соответствующую виртуальную машину, эмулятор или что-нибудь подобное).
Данная программа считывает с жесткого диска тот же самый файл (имеющий имя ip_tmp.txt), определяет число байтов в нем, а также число строк (путем подсчета числа концов строк – байтов \n. Сравнение с контрольной строкой вида 127.0.0.1.А не производилось, однако, даже несмотря на это, время выполнения программы лежало в интервале 0,05…0,07 секунд. Естественно, если добавить еще операцию сравнения каждой из строк с контрольной строкой, время выполнения будет еще выше.
Тем самым, этот способ, по крайней мере, не лучше, чем предыдущий. Однако, он, в отличие от предыдущего, приводит к гораздо большим затратам оперативной памяти.
Так, если в предыдущем способе для переменной fname выделялось лишь 126 байтов (при помощи функции malloc; отметим, что это значение выбрано произвольно, с запасом), то в последнем способе переменной fname1 требуется 6 МБ с лишним оперативной памяти (так как файл считывается сразу).
Примечание: впрочем, в первом способе, скорее всего, оперативной памяти расходуется, все же, больше, чем 126 Б. Ибо, операционная система может, кэшировать данные на диск еще до того, как они понадобятся (опережающее чтение).
Поэтому можно сказать, что второй способ – не лучше. Поэтому соответствующая программа не доделывалась до конца, обработку строк она не производит – раз и без этого работает не быстрее.
С целью получить от Ubuntu максимальное быстродействие, переходим в чистую консоль путем нажатия
CTRL + ALT + F1
Ubuntu будет работать БЕЗ графического интерфейса, будет лишь чистая консоль, т.е. черный экран с командной строкой. Обратно вернуться в графический режим можно путем нажатияCTRL + ALT + F7Вновь запускаем первую программу. Замеры времени дают значения 0,046…0,062 сек.
В самом деле, программа заработала немного побыстрее. Однако, совсем-совсем немного – буквально на 10%. Т.е. выигрыш во времени очень несущественный. Это означает, что имеющийся стандартный графический интерфейс Ubuntu практически не замедляет работу программы. Впрочем, современная Ubuntu и так довольно медленная.
| Время, затраченное на просмотр и обработку всех строк файла, секунды | Число строк в файле, тыс. шт. | Где проходило тестирование | Способ запуска программы |
| fopen+fgets: | |||
| 0,061 | 409,965 | Локальный компьютер (Windows 7 / Vmware Player / Linux (Ubuntu) ) | Из консоли, открытой из графического интерфейса |
| 0,052 | 409,965 | Локальный компьютер (Windows 7 / Vmware Player / Linux (Ubuntu) ) | Из чистой консоли (графический интерфейс отключен) |
| 0,025 | 409,965 | Типичный хостинг в сети интернет на Linux | Консоль сервера (по протоколу SSH) |
| 0,025 | 409,965 | Типичный хостинг в сети интернет на Linux |
Из программы, написанной на языке РНР с использованием команд: system ` ` exec |
Кстати, вот текст (код) программы PHP, использовавшей указанные три команды для выполнения озвученной выше цели (открытие файла ip_tmp.txt' и сравнение каждой из его строк с наперед заданной строкой):
<?php
//В Linux - разрешаем запускать загруженный файл
//Без этой строки файл, скорее всего, не запустится
system('chmod +x file_c');
//При помощи команды exec:
$output = exec("./file_c");
echo "<pre>$output</pre>\n";
//При помощи команды ` ` (обратные апострофы):
$output = `./file_c`;
echo "<pre>$output</pre>\n";
//При помощи команды system:
echo '<pre>';
// Выводит весь результат шелл-команды "file_c", и возвращает
// последнюю строку вывода в переменной $last_line. Сохраняет код возврата шелл-команды в $retval.
$last_line = system('./file_c', $retval);
// Выводим дополнительную информацию
echo '</pre>
<hr />Последняя строка вывода: ' . mb_convert_encoding($last_line, "windows-1251", "utf-8" ) . '
<hr />Код возврата: ' . mb_convert_encoding($retval, "utf-8", "windows-1251" );
?>
Естественно, запускаемый (шелл) файл file_c должен находиться в том же самом каталоге, что и РНР-файл, из которого первый запускается. Иначе – необходимо будет указать путь к нему.
Кстати, следует учесть еще вот что
Есть немалая вероятность, что программа на С, будучи скомпилированной без ошибок под Linux на локальном компьютере «вдруг» откажется работать на сервере. Запуск ее при помощи РНР особо не прояснит ситуацию (ибо ряд серверов настроен так, что подавляют вывод сообщений об ошибках). А вот консоль сервера (с использованием протокола SSH) даст больше информации. Например, при запуске программы могут появиться ошибки такого рода:
/lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.14' not found (required by …)
Такие ошибки означают, что версии динамических (судя по расширению .so) библиотек операционной системы Linux на локальном компьютере и на сервере не совпадают. Соответственно, исполняемый (бинарный) файл, скомпилированный на локальном компьютере, может не заработать на сервере (и, вообще говоря, наоборот).
Какой выход? Очень простой: необходимо скопировать на сервер не исполняемый файл, а исходный код (т.е. текст) программы и скомпилировать ее уже там. Для этого, конечно, потребуется консоль с доступом по протоколу SSH.
Впрочем, вполне возможно использование для этих целей… и РНР (все-таки, до чего же универсальный и удобный язык). Если написать в коде PHP что-то вроде:
exec("gcc -o file_binary file_text.c")
Затем – сохранить файл РНР на сервере и запустить через браузер.
Правда, это пока не проверялось, но, вроде как, работать должно. Тогда можно будет вполне обойтись без консольного доступа.
Естественно, следует иметь в виду, что при хранении программы на РНР на сервере, имеющей подобные возможности, возникает дополнительная опасность несанкционированного управления содержимым сайта (т.е., проще говоря, его взлома). Поэтому, видимо, не следует ею пользоваться без особой надобности.
Выводы
Таким образом, можно сделать выводы. Язык РНР, при его оптимальном использовании, как ни странно, всего лишь в 5…6 раз медленнее обрабатывает строки текстового файла объемом 6,1 МБ, имеющегося на жестком диске локального компьютера, по сравнению с языком С. А ведь С – это наиболее быстрый язык – среди всех известных языков, доступных для прикладного программиста. Быстрее – разве что Ассемблер. Ну, или программа, написанная на машинных кодах (что в настоящее время – уже редкость).
Тогда как на сервере С программа работает весьма охотнее. Так, скорость программы, написанной на языке С и запущенной на сервере, в среднем, почти в 12 раз выше, чем программа на чистом PHP, выполняющая ту же самую задачу.
Причина тому – объяснима. Ведь на локальном компьютере программа запускалась через виртуальную машину (которая, несомненно, потребляет определенные ресурсы времени). Кроме того, нельзя сбрасывать со счетов еще и тот факт, что в качестве серверов используются, как правило, достаточно мощные компьютеры. Поэтому и соответствующая разница в скоростях является, судя по предыдущей таблице, как минимум, двухкратной.
Надо сказать, что ВООБЩЕ не обнаружено разницы в скорости использования трех указанных команд РНР, при помощи которых запускалась на сервере консольная программа на С:
system
` ` (обратные апострофы)
exec
Это означает, что можно с одинаковой эффективностью (в плане скорости работы) использовать любую из них. Разница лишь – в их функционале и привычках разработчика.
Вероятно, программа, написанная на С++ (и, тем более, на С#) будет работать дольше, чем на С. Ибо, как известно, программы, выполненные на С++, работают в целом дольше, чем те, что сделаны на чистом С. Что вызвано использованием объектно-ориентированного подхода в С++ (ведь на создание объектов и оперирование ими затрачивается дополнительное время; также затрачивается дополнительное количество оперативной памяти).
РНР & C
Итак. Можно обрабатывать указанный файл на чистом РНР. При этом минимальное (в среднем, при использовании пары функций fopen+explode) время обработки составит 0,29 сек.
А можно – либо на чистом С, либо, что проще – вызывать соответствующую функцию (написанную на С) из программного кода PHP. Время обработки файла составит при этом 0,025 сек. Это позволит выполнять обработку файла быстрее в 0,29/0,025 = 11 с лишним раз.
При этом файл, например, объемом 640 МБ будет обработан примерно за 2,5 сек – и это на типичном, не слишком быстром хостинге. Что, как видится, вполне приемлемо, по крайней мере, для не слишком нагруженных сайтов (а таковых – не так уж много, на самом деле).
В настоящее время среди вебмастеров популярен также язык Python (Питон). Вроде бы, программы на нем работают немного быстрее тех, что написаны на РНР. Однако, очевидно, что быстрее «сишных» они все равно не будут: ведь Python – это скриптовый, некомпилируемый язык, равно как и РНР. Так есть ли смысл в его использовании в угоду РНР?
Наверное, нет (за исключением случаев, когда вся или большая часть сайта уже выполнена на Питоне). Если нужна скорость разработки и удобство – тогда уж РНР. Ну, а если приоритетнее – скорость функционирования сайта, тогда – С.
Ну, а, наконец, если в приоритетах – и то, и другое, тогда… тоже РНР, но со включениями модулей, написанных на С. На мой взгляд, это – оптимальный вариант: будет достигнута как высокая скорость разработки, так и высокая скорость функционирования сайта.
Конечно, очень нежелательно, чтобы имена таких модулей, не говоря уже о параметрах, с которыми они запускаются, определялись в программе PHP динамически: это увеличит вероятность взлома сайта.