Последнее обновление:
О неочевидных ошибках функции loadXML() – PHP
Функция loadXML() в языке РНР производит загрузка XML из строки – так сказано в мануалах по PHP. Она возвращает TRUE в случае успешного завершения или FALSE в случае возникновения ошибки. Если вызвана статически, возвращает объект класса DOMDocument или FALSE в случае возникновения ошибки.
Какие могут быть у нее ошибки?
Мануал сообщает лишь о некоторых видах ошибок:
- Если через аргумент source передана пустая строка, будет сгенерировано предупреждение. Это предупреждение генерируется не libxml, поэтому оно не может быть обработано функциями обработки ошибок libxml.
- Этот метод может быть вызван статически, но при этом будет сгенерирована ошибка уровня E_STRICT.
Из комментариев в мануалу можно прочитать еще о возможных проблемах с функцией loadXML():
- Если входной файл более 10МБ,
- Если передаваемая на вход функции строка не является корректным XML-кодом,
- Если передаваемые html-сущности (типа ) не допускаются декларацией DOCTYPE документа.
И, в общем-то, всё. Там, однако, НЕ указан еще один важнейший класс ошибок, которые могут быть допущены при работе с loadXML():
несоответствие кодировок (!!!)
Надо сказать, что это – и не мудрено, что не указано. Дело в том, что такая ошибка – достаточно нетипичная, редкая и потому – очень трудно ее отловить (скажем, типичные автоматизированные тесты, скорее всего, не выявят ее). И тем она – коварнее. Но, увы, именно она может «почему-то» вызвать капитальный сбой в работе сайта.
Ниже мы рассмотрим подробно два вида ошибок: ввода некорректного XML и несоответствие кодировок.
1. Некорректный XML
Виды некорректного XML могут быть подразделены на два основных:
- Неверный формат XML-тегов,
- Неверные html-сущности.
Формат html-тегов может быть неверным, к примеру, если не закрыт тот или иной тег; или если тег сам по себе написан неверно. Вот типичные примеры неверных тегов, исходя из стандарта XML:
<br> (этот тег – самозакрывающийся и должен быть написан так: <br/>)
< div> (присутствует пробел там, где его быть не должно)
<div>…. и отсутствует закрывающий тег </div>
< / div> (присутствуют лишние пробелы)
HTML-сущности имеют два формата написания:
<(отображается браузером как символ<),©(знак авторского права – копирайт, его также можно записать и в другом формате:©),
Следует заметить, что и то, и другое описание имеет характерные признаки: начинается с символа & (амперсанд) и оканчивается ; (точка с запятой). Между ними могут быть либо латинские буквы, либо знак # и цифры. Однако, далеко НЕ ВСЕ буквы и цифры допустимы. В частности, существуют некорректные (недопустимые) html-сущности. Например, сущность ©f; - недопустима (в отличие от ©). Точно также и с цифрами – отнюдь не любое их сочетание является допустимым (корректным).
Так вот, если на вход функции loadxml() подать строку, содержащую некорректные теги или некорректную html-сущность, будет сгенерировано предупреждение, при этом результатом этой функции будет, как уже говорилось, FALSE. Т.е. создание DOM для такой строки не произойдет – со всеми вытекающими последствиями.
Например, хрестоматийным некорректным XML-кодом является символ одиночного амперсанда &. Вместо этого следует использовать &. Т.е. сам по себе амперсанд допустим в XML-коде только в составе ДОПУСТИМЫХ html-сущностей. Иными словами, если Вы решили передать во входную строку функции loadxml(), к примеру, программный код вида
if($x && $y){…}
то необходимо превратить в корректные html-сущности амперсанды, которые, по крайней мере, не являются началом тех или иных html-сущностей. Т.е. этот код перед передачей функции loadxml() нужно будет преобразовать следующим образом:
if($xamp; && $amp;y){…}
Увы. Да, длинновато получится, но зато – будет работать без проблем в качестве аргумента этой функции.
Ну, с некорректным XML-кодом, вроде бы, всё ясно. Переходим ко второму виду ошибок, пока еще НЕ описанных в мануалах и иных руководствах.
2. Несоответствие кодировок
Посмотрим типичный пример применения функции loadxml():
- header('Content-Type:text/html; charset=windows-1251');
- //header('Content-Type:text/html; charset=UTF-8');
- define('XMLHead', "<?xml version='1.0' encoding='windows-1251'?>");
- $domdocument = new domDocument('1.0', 'windows-1251');
- $domdocument->loadXML(XMLHead . "<html><body>" . $string_XML . "</body></html>");
Как видим, здесь присутствует, как минимум, ПЯТЬ видов кодировок:
- Кодировка, отправляемая сервером браузеру (чтобы тот знал, в какой кодировке ему следует воспринимать принятый от сервера код html),
- Кодировка, задаваемая на вход функции loadxml(),
Кодировка строки $string_XML.
- Кодировка, в которой создается новый объект domDocument,
Внутренняя кодировка скрипта РНР.
Конечно, вроде бы, самоочевидно, что первые три кодировки должны бы совпадать. Это да, верно. Но, увы, на практике такое бывает далеко не всегда. Даже если учесть, что в настоящее время достаточно многие сайты делаются в единой (ныне любимой народами) кодировке UTF-8.
Ибо даже и в таком случае проблема с разночтением кодировок может возникнуть, например, если строка $string_XML получена из внешнего источника (например, прочитана из файла, загруженного на сервер пользователем). Причем, автоопределение кодировок далеко не всегда срабатывает правильно – это уж из практики.
Наверное, для более-менее специалистов это очевидно, но, все-таки, обратим внимание: на функции автоопределения кодировки, имеющиеся в РНР, серьезно полагаться не следует! Их можно использовать, в основном, лишь в отладочных, тестовых, учебных, справочных и иных аналогичных целях. Но, не для серьезной работы. Потому что в самый неожиданный момент они могут подвести.
Кроме того, бывают и программистские ошибки, когда разработчик, не обратив внимания на неверную кодировку, написал программный код, который работает «правильно». Т.е. код, конечно, выдает более-менее правильные результаты, но… не всегда. А когда он может выдать неверные? Тогда, когда на вход функции loadxml() будут поданы КРИТИЧЕСКИЕ данные. В таком случае, если первые три кодировки не будут совпадать, функция loadxml() выдаст совершенно не тот результат, который от нее, быть может, ожидали.
Рассмотрим простой пример ошибок функции loadxml() в результате применения неверных кодировок
Создадим четыре файла. Два из них в кодировке windows-1251 (cp1251) и два – в кодировке utf-8. Для наглядности, названия и содержимое каждого из файлов показаны на рисунках:
without_I_utf8.html
Русские буквы.
<div>тег div</div>
& ῴ
without_I.html
Русские буквы.
<div>тег div</div>
& ῴ
with_I_utf8.html
Русские буквы. И здесь есть буква И.
<div>тег div</div>
& ῴ
with_I.html
Русские буквы. И здесь есть буква И.
<div>тег div</div>
& ῴ


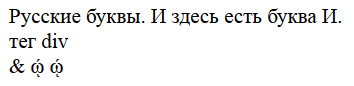
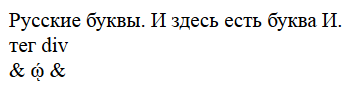
По сути, файлы различаются, разве что, исходными кодировками, в которых сохранено их содержимое и, что самое главное, наличие/отсутствием фразы «И здесь есть буква И.».
Далее, вот такой код РНР (версия РНР 5.3), при помощи которого мы будем тестировать содержимое этих файлов:
- <?php
- /* Установка внутренней кодировки этого скрипта в UTF-8 */
mb_internal_encoding("UTF-8");
- $internal_enc = mb_internal_encoding();
- header('Content-Type:text/html; charset=WINDOWS-1251');
//header('Content-Type:text/html; charset=UTF-8');
- echo $without_I = file_get_contents('without_I.html').'<br/>'.'<br/>'; // Русские буквы. тег div & < ῴ
- echo $with_I = file_get_contents('with_I.html').'<br/>'.'<br/>'; //Русские буквы. И здесь есть буква И. тег div & < ῴ
- echo $without_I_utf8 = file_get_contents('without_I_utf8.html').'<br/>'.'<br/>'; //п»їР СѓСЃСЃРєРёРµ Р±СѓРєРІС‹. тег div & < ῴ
- echo $with_I_utf8 = file_get_contents('with_I_utf8.html').'<br/>'.'<br/>'; //п»їР СѓСЃСЃРєРёРµ Р±СѓРєРІС‹. Р? здесь есть Р±СѓРєРІР° Р?. тег div & < ῴ бїґ
- define('XMLHead', "<?xml version='1.0' encoding='windows-1251'?>");
- $domdocument = new domDocument('1.0', 'windows-1251');
- $domdocument->loadXML(XMLHead . "<html><body>" . $without_I . "</body></html>");
- echo 'without_I - OK'.'<br/>'; // without_I - OK
- $domdocument->loadXML(XMLHead . "<html><body>" . $with_I . "</body></html>");
- echo 'with_I - OK'.'<br/>'; // with_I - OK
- $domdocument->loadXML(XMLHead . "<html><body>" . $without_I_utf8 . "</body></html>");
- echo 'without_I_utf8 - OK'.'<br/>'; // without_I_utf8 - OK
- $domdocument->loadXML(XMLHead . "<html><body>" . $with_I_utf8 . "</body></html>");
- echo 'with_I_utf8 - OK'.'<br/>';
- /*
- Warning: DOMDocument::loadXML() [domdocument.loadxml]: switching encoding: encoder error in Entity, line: 1 in ...xmload.php on line 26
- Warning: DOMDocument::loadXML() [domdocument.loadxml]: Blank needed here in Entity, line: 1 in ...xmload.php on line 26
- Warning: DOMDocument::loadXML() [domdocument.loadxml]: input conversion failed due to input error, bytes 0x98 0x20 0xD0 0xB7 in ...xmload.php on line 26
- Warning: DOMDocument::loadXML() [domdocument.loadxml]: encoder errorparsing XML declaration: '?>' expected in Entity, line: 1 in ...xmload.php on line 26
- Warning: DOMDocument::loadXML() [domdocument.loadxml]: Start tag expected, '<' not found in Entity, line: 1 in ...xmload.php on line 26 with_I_utf8 - OK
- */
Серым цветом в программном коде отображены результаты вывода (echo).
Обсуждение результатов
Итак, внутренняя кодировка скрипта установлена в utf-8, а кодировки объекта domDocument и функции loadxml() – в windows-1251. Как видно, проблемы наблюдаются лишь для ЧЕТВЕРТОГО (по очередности использования) файла, имеющего имя with_I_utf8.html. В нем, во-первых, содержится та самая дополнительная строка «И здесь есть буква И.», а. во-вторых, он закодирован в отличной от windows-1251 кодировке, а именно - в utf-8.
Любопытно, что содержимое файла without_I_utf8.html (закодированного в utf-8!!), содержащего русские буквы, вполне корректно обрабатывается функцией loadxml(); ни ошибок, ни предупреждений она не выдает. А вот с файлом with_I_utf8.html – проблема.
А все дело в… заглавной русской букве И. Которая присутствует в файле with_I_utf8.html, но отсутствует в файле without_I_utf8.html.
Собственно, потому эти файлы и содержат в своих названиях символ I.
Также видно, что подобная проблема с русской буквой заглавной И имеется только в строках из файлов с «чужеродной» кодировкой, не соответствующей кодировке функции loadxml() и объекта domDocument. Если же строки закодированы в «родной» кодировке (в данном случае – windows-1251), то проблемы… нет. Это означает, что если разработчик по оплошности не предусмотрит возможность различия кодировок входных строк, функции loadxml() и объекта domDocument, то в НЕКОТРЫХ случаях это может привести к краху работы сайта. Хотя, повторимся, если специально не знать об этом нюансе, отловить сию ошибку, как Вы понимаете, практически невозможно. Ну, если только очень повезет и Вы при тестировании зададите заглавную букву И в качестве компонента входной строки. А если так – позадавали несколько кириллических строк без этой буквы – то вполне может статься, что баг в Вашем скрипте выявлен не будет.
Надо сказать. что из состава русских букв такая проблема встречается лишь только с этой буквой. Все остальные, в том числе строчная «и», вполне корректно обрабатываются функцией loadxml() вне зависимости от того, имеется ли указанное разночтение кодировок или нет. Мы уже рассматривали эту проблему.
Что это было?
Сложно сказать. То ли это – баг PHP. То ли где-то в недрах кода, реализующего функцию loadxml(), используется то самое ДВОЙНОЕ перекодирование (которое приводит к проблеме только для заглавной буквы И) входных строк в случае, если кодировки не совпадают. То ли еще что. Но, факт остается фактом: на этом разработчик может сильно поскользнуться.
Естественно, речь здесь идет только о кириллице
Т.е. о русских буквах. И о кодировках utf-8 и windows-1251. А как поведет себя функция loadxml() в случае использования других кодировок, отличных от utf-8 и windows-1251? Как поведет себя эта функция при использовании других букв, не латинских и не кириллических?... Кто ж его знает. Здесь – только экспериментальное глобальное исследование.
Отсюда вытекает следующий совет: НЕ стоит злоупотреблять использованием разных национальных алфавитов на сайте без особой необходимости (даже, повторимся, в любимой ныне народами "универсальной" кодировке utf-8). Как поведет себя та или иная функция РНР на некоторых национальных символах? В общем случае, сказать сложно. Поэтому, если точного понимания в этом нет, лучше обойтись старым деловским методом: использованием html-сущностей. Да, это приведет к увеличению объема html-кода в несколько раз. Но, зато застрахует работу сайта, по крайней мере, в обсуждаемом аспекте.
Так что, уважаемые разработчики на РНР: не стоит думать, что раз уж Вы используете «универсальную и оптимальную» кодировку utf-8, то, якобы, «с кодировками проблем не будет». Как видите, проблемы вполне могут быть, причем они, еще раз, трудно диагностируемые.
А что будет, если назначить кодировку utf-8 функции loadxml() и объекту domDocument?
При этом проблема возникает, наоборот, с содержимым тех файлов, которые закодированы в кодировке windows-1251. Характерно, что теперь уже проблема есть вне зависимости от того, присутствует ли заглавная буква И в файле (т.е. во входной строке функции loadxml) или нет. Вот такая уж она интересная, эта буква И.
А как быть, если сайт таки настроен на utf-8, а строка XML пришла в другой кодировке?
Если при обработке строки используется функция loadxml(), то возможны два выхода:
- Указать в
loadxml()(а также и в объектеDOMDocument) исходную кодировку строки, а дальше, после обработки, перекодировать ее в utf-8; - Сразу перекодировать строку в utf-8 и работать только в этой кодировке. Однако, при этом не стоит со 100% уверенностью полагаться на функции, которые «автоматически определяют» кодировку. По нашему опыту, они вполне способны дать сбой даже в пределах двух указанных выше «невинных» кодировках. Т.е. использовать подобные функции, конечно, можно… но, осторожно.
Немного оффтопа
Таким образом, как видим: не то, что мануалов по PHP, но даже и специализированных статей в интернете совершенно недостаточно для того, чтобы выполнить действительно корректный РНР-код. И таких примеров (в частности, в РНР), на самом деле, не столь уж мало. А мало-мальски серьезный разработчик с ними, разумеется, так или иначе вынужден быть знакомым.
Отсюда можно сделать очевидный вывод: когда Вам в интернете или еще где на Ваш вопрос о том, как функционирует то или это начинают говорить в ответ – читайте, мол, мануалы, спрашивайте Google и т.п., то Вы сразу (точнее – мгновенно) можете для себя понять: стало быть, Ваш «советчик» - начинающий и, дай бог, если хоть научился писать приложения уровня «Hello World». А возможно, плюс к тому, еще и (платный) тролль. Которому поставлена задача: поссорить всех и вся, в том числе – и программистов между собой. Стоит ли у него что-то пытаться спрашивать дальше или нет, стоит ли с ним общаться вообще – решать, конечно, Вам. На наш искренний взгляд – НЕ стоит. Ибо серьезный программист НИКОГДА не будет отсылать человека к мануалам, как к истине в последней инстанции; у него, скорее всего, будет огромный опыт и масса практических случаев, когда эти самые мануалы помочь не могли, а то и противоречили практике.
Выводы о возможных ошибках в loadxml()
Итак, функция loadxml() (как минимум, в версии PHP 5.3), по нашему опыту, выдаст предупреждение или ошибку в случаях:
- Если входная строка – пустая,
- Если входная строка представляет собой некорректный XML,
- Если не соответствуют кодировки входной строки и в функции loadxml(), равно как и в объекте DOMDocument.
Другие программисты сообщают также о следующих ошибках в loadxml():
- Если объем входной строки превышает 10 МБ,
- Если передаваемые html-сущности (типа
) не допускаются декларацией DOCTYPE документа.
Поэтому при использовании этой функции следует очень тщательно подходить не только к корректности XML-строки, но и к согласованию кодировок. А также (не обращая внимания на мануалы!) - тестировать, тестировать, тестировать...
Вполне возможно, что в последующих версиях PHP эта проблема (будет) устранена. Нам об этом пока неизвестно. Если Вы что-то знаете больше – напишите, пожалуйста, об этом в комментариях.
Кстати, в PHP есть еще аналогичная функция – loadHTML()
Эта функция осуществляет загрузку HTML-строки.
Интересно, что с этой функцией проблем с заглавной буквой И не возникает, так как кодировки там не указываются. Но, конечно, к некорректному html-коду эта функция также чувствительна и выдает предупреждение. При этом самозакрывающиеся теги, в отличие от loadxml(), закрывать уже необязательно. Т.е. тег <br/> будет корректным, равно как и <br>. Т.е. эта функция более «лояльна» к входным данным. Это и понятно, так как HTML тоже более лоялен (тем более, HTML5, который, к сожалению, допускает вообще очень многие вольности), чем XML.
Однако, эта лояльность – одновременно и ее недостаток. Например, тогда, когда хотим получить чистый, корректный XML или проверить корректность уже имеющегося XML, содержащегося в строке. Функция loadHTML() здесь, увы, не слишком хороший помощник. Тогда как loadxml() нередко как раз и используется на практике для такой проверки. В самом деле, если строка некорректна в смысле XML, то loadxml() выдаст FALSE. Использование этой функции - один из залогов того, что на сайт не попадет некорректный XML-код, не будет занесена SQL-инъекция. Только вот нужно с кодировками быть внимательными.