Последнее обновление:
Изучаем скорость работы хостинга
Хостинг – это услуга, в рамках которой предоставляется место на сервере для хранения файлов сайта. Одновременно хостингом иногда называется и сам сервер.
Хостинги бывают разные: хорошие, плохие, надежные и не очень. Существует немало сервисов, которые предоставляют рейтинги хостингов и их сопоставление по ряду технических параметров. Например, этот.
Правда, там в списке почему-то нет ряда очень известных хостингов.
Кроме того, на подавляющем большинстве серверов, на которых расположены хостинги, приведены некоторые параметры работоспособности, определенные лишь на конкретный момент времени.
Можно, конечно, использовать сервис скорости, например, при помощи этого сервиса. Однако, понятно, что для более тщательного анализа необходимы, в первую очередь, средние параметры. Например, среднее время отдачи файла, определенное в течение длительного времени, например, неделя, месяц, квартал… Именно, опираясь на такие сроки, и можно говорить о маломальской пригодности хостинга для использования.
Один из способов тестирования хостинга
Т.е. можно, конечно, использовать тот же webpagetest раз 100…1000 подряд – и так на протяжении многих недель. Однако, во-первых, это утомительно (правда, можно написать парсер – но это тоже работа или затраты). Во-вторых, вероятно, при достаточно высоком объеме работы на сервисе сработают некие ограничения, поэтому придется вносить оплату. Ну, а очень частую проверку, видимо, не разрешат.
Поэтому – какой выход? Выход – использовать для этого… роботов поисковых систем. Они, собственно, и так посещают сайты (с разной периодичностью, но, чем популярнее сайт, тем чаще и больше сканируют файлов). К тому же, скажем, в Google, в Вебмастере накапливается аналитика, в частности, динамика таких показателей, как время, затраченное на загрузку страницы (в миллисекундах), количество килобайтов, загруженных за день, количество сканированных страниц в день. Этой информацией и можно воспользоваться для того, чтобы провести анализ.
Примечание. При помощи этой информации возможно будет проверить только тот хостинг, на котором уже установлен и некоторое время работает Ваш сайт. Чужие хостинги проверить таким образом не получится. Более того, сайт еще и должен быть проиндексированным.
В настоящее время в Вебмастере Гугл дается аналитика (максимум – на 90 дней), выглядящая примерно следующим образом:
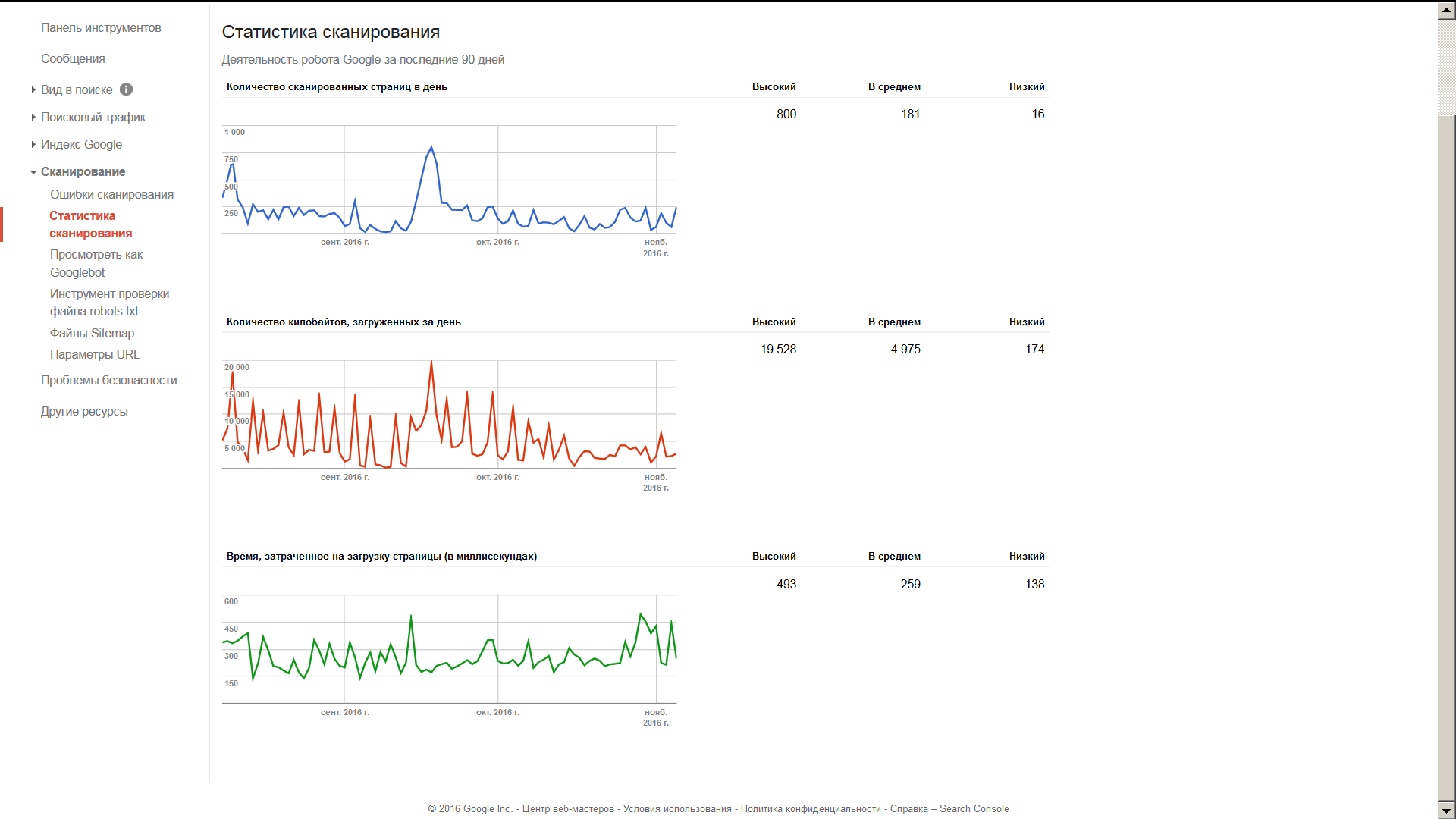
Если поднести указатель мыши к какому-либо графику, можно узнать конкретное цифровое значение того или иного показателя.
Однако, для анализа нам понадобится таблица этих значений. Раньше Вебмастер, вроде бы, позволял выводить данные в табличном виде. Сейчас, похоже, такой возможности нет.
Как быть?
Такой вопрос я задавал в форумах, в том числе и в сообществе вебмастеров Google. Там, так сказать, эксперты мне отвечали, что, мол, придется анализировать логи сервера(!...) на предмет наличия в них информации о деятельности робота Googlebot и оттуда уже выявлять информацию.
Правда, непонятно, как из логов сервера добыть данные о количестве о времени, затраченном на загрузку страницы (в миллисекундах).
И что, мол, такую информацию мне не получить.
А выход-то простой
На самом деле, все просто. Ибо каждый имеет право на информацию, касающуюся его лично, если она не представляет собой государственную тайну.
Конечно, эта информация в цифровом виде должна содержаться в исходном коде страницы Вебмастера, извлечь ее оттуда несложно. Однако, Гугл запрещает получать информацию в обход стандартного интерфейса. Запрещает и получать исходные коды своих сервисов.
Понятно, что (по крайней мере, в рамках законодательства России) подобное заявление звучит некорректным. Скажем, если открыть исходный код Вебмастера и посмотреть там информацию – это будет нарушение условий использования, в соответствии с этим?
Нет, не будет. В этой части условия противоречат российскому законодательству. Ибо, во-первых, посмотреть – это не означает «взламывать» или «использовать» (а, тем более – копировать, распространять и т.д.). Практически любой браузер дает возможность свободного просмотра исходного кода веб-страницы (ибо это – открытый исходный код), это не является нарушением законодательства; нарушением может быть лишь использование ее таким образом, которым не разрешает лицензия. Во-вторых, если из этой всей информации будет использоваться та и только та информация, которая касается пользователя лично, но которую он не имеет возможности увидеть в интерфейсе Вебмастера (или если возможность есть, но она затруднена)? Естественно, пользователь должен получить беспрепятственный доступ ко всей той информации, которая касается его (и/или его сайта) лично.
То есть, в сухом остатке, здесь можно подать в суд иск против Google за несоответствие условий пользования Вебмастером законодательству той страны, на территории которой такое пользование осуществляется. И разбирательство будет происходить вовсе не по законам Калифорнии. Но, как видится, это все – лишние потери времени. Да и попросту не хочется с этим связываться.
Поэтому поступаем сложнее, в соответствии с условиями использования. По очереди подносим указатель мыши к КАЖДОЙ точке графика, как-то так:
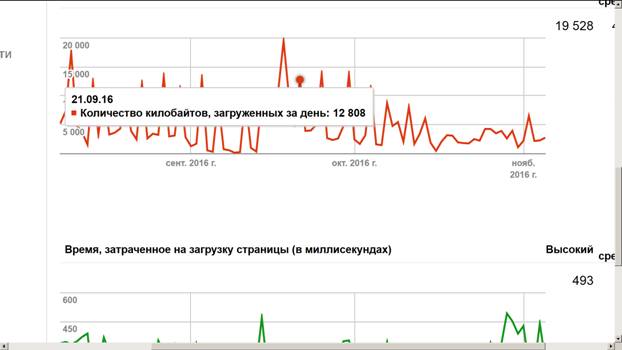
Затем пунктуальнейшим образом, используя интерфейсы Гугл, записываем карандашом увиденные дату и показание куда-нибудь, например, в школьную тетрадку, в столбик. Ну, как вариант, на бумажку или в Excel. Пока что, вроде как, Microsoft еще не запрещает заносить данные в таблицы Excel?
И так, понимаете ли, точка за точкой… на всех указанных трех графиках. Кропотливая такая работа, неспешная. Никоим образом не вмешивающаяся в дела интерфейса Вебмастера, не пытающаяся копировать, изменять, распространять, продавать или сдавать в аренду какие-либо элементы Служб Google и относящегося к ним программного обеспечения, осуществлять обратную разработку и вовсе не пытающаяся извлечь исходный код этого ПО. Ну, да ладно.
В общем, как уже договорились, из исходного кода Вебмастера Гугл мы не копируем. Поэтому из тетрадки переносим данные в Excel и располагаем рядом друг с другом – в виде столбцов. Делать анализ-то Гугл нам запрещает. Да и не может запретить.
Как итог наших потуг, получится что-то в таком роде:
| Дата | Время, затраченное на загрузку страницы (в миллисекундах) | Количество килобайтов, загруженных за день | Количество сканированных страниц в день |
| 07.08.2016 | 371 | 7 677 | 340 |
| 08.08.2016 | 338 | 5 220 | 333 |
| 09.08.2016 | 345 | 7 395 | 500 |
| 10.08.2016 | 333 | 17 584 | 691 |
| 11.08.2016 | 347 | 4 921 | 315 |
| 12.08.2016 | 371 | 3 730 | 245 |
| 13.08.2016 | 389 | 1 563 | 95 |
| 14.08.2016 | 138 | 12 461 | 273 |
| 15.08.2016 | 222 | 3 287 | 203 |
| 16.08.2016 | 368 | 10 367 | 218 |
| 17.08.2016 | 293 | 3 316 | 133 |
| 18.08.2016 | 207 | 3 645 | 222 |
| 19.08.2016 | 200 | 4 335 | 134 |
| 20.08.2016 | 182 | 10 346 | 246 |
| 21.08.2016 | 167 | 3 949 | 251 |
| 22.08.2016 | 241 | 2 488 | 164 |
| 23.08.2016 | 172 | 12 146 | 240 |
| 24.08.2016 | 139 | 2 644 | 174 |
| 25.08.2016 | 197 | 3 466 | 214 |
| 26.08.2016 | 352 | 3 267 | 217 |
| 27.08.2016 | 292 | 13 394 | 163 |
| 28.08.2016 | 216 | 2 999 | 160 |
| 29.08.2016 | 330 | 3 148 | 184 |
| 30.08.2016 | 247 | 11 199 | 191 |
| 31.08.2016 | 208 | 2 862 | 147 |
| 01.09.2016 | 199 | 1 302 | 71 |
| 02.09.2016 | 337 | 1 738 | 91 |
| 03.09.2016 | 256 | 13 086 | 303 |
| 04.09.2016 | 141 | 569 | 52 |
| 05.09.2016 | 224 | 345 | 17 |
| 06.09.2016 | 282 | 9 232 | 81 |
| 07.09.2016 | 177 | 776 | 45 |
| 08.09.2016 | 284 | 612 | 22 |
| 09.09.2016 | 232 | 174 | 16 |
| 10.09.2016 | 327 | 296 | 22 |
| 11.09.2016 | 255 | 9 644 | 117 |
| 12.09.2016 | 168 | 1 019 | 51 |
| 13.09.2016 | 225 | 373 | 28 |
| 14.09.2016 | 472 | 9 499 | 111 |
| 15.09.2016 | 213 | 6 946 | 300 |
| 16.09.2016 | 175 | 7 988 | 508 |
| 17.09.2016 | 187 | 10 745 | 707 |
| 18.09.2016 | 172 | 19 528 | 800 |
| 19.09.2016 | 208 | 9 828 | 652 |
| 20.09.2016 | 217 | 5 267 | 286 |
| 21.09.2016 | 225 | 12 808 | 284 |
| 22.09.2016 | 192 | 3 944 | 223 |
| 23.09.2016 | 205 | 4 019 | 221 |
| 24.09.2016 | 221 | 5 035 | 220 |
| 25.09.2016 | 240 | 13 764 | 262 |
| 26.09.2016 | 217 | 2 710 | 124 |
| 27.09.2016 | 234 | 2 379 | 117 |
| 28.09.2016 | 289 | 2 639 | 143 |
| 29.09.2016 | 349 | 4 818 | 245 |
| 30.09.2016 | 353 | 13 698 | 253 |
| 01.10.2016 | 236 | 2 466 | 142 |
| 02.10.2016 | 221 | 1 696 | 93 |
| 03.10.2016 | 223 | 3 177 | 116 |
| 04.10.2016 | 242 | 11 247 | 216 |
| 05.10.2016 | 209 | 1 622 | 92 |
| 06.10.2016 | 236 | 1 497 | 66 |
| 07.10.2016 | 345 | 8 761 | 72 |
| 08.10.2016 | 197 | 4 796 | 220 |
| 09.10.2016 | 229 | 5 485 | 95 |
| 10.10.2016 | 242 | 2 083 | 106 |
| 11.10.2016 | 263 | 8 049 | 102 |
| 12.10.2016 | 173 | 1 687 | 88 |
| 13.10.2016 | 216 | 3 448 | 120 |
| 14.10.2016 | 228 | 6 103 | 155 |
| 15.10.2016 | 306 | 1 877 | 51 |
| 16.10.2016 | 271 | 507 | 23 |
| 17.10.2016 | 253 | 2 116 | 82 |
| 18.10.2016 | 211 | 3 204 | 164 |
| 19.10.2016 | 235 | 3 135 | 57 |
| 20.10.2016 | 249 | 1 976 | 39 |
| 21.10.2016 | 236 | 1 848 | 90 |
| 22.10.2016 | 206 | 1 790 | 55 |
| 23.10.2016 | 216 | 2 534 | 62 |
| 24.10.2016 | 219 | 2 268 | 111 |
| 25.10.2016 | 224 | 4 290 | 223 |
| 26.10.2016 | 340 | 4 282 | 239 |
| 27.10.2016 | 260 | 3 534 | 150 |
| 28.10.2016 | 337 | 3 950 | 114 |
| 29.10.2016 | 493 | 2 642 | 122 |
| 30.10.2016 | 453 | 3 971 | 241 |
| 31.10.2016 | 388 | 1 131 | 36 |
| 01.11.2016 | 428 | 2 242 | 63 |
| 02.11.2016 | 224 | 6 540 | 190 |
| 03.11.2016 | 214 | 2 216 | 102 |
| 04.11.2016 | 441 | 2 305 | 63 |
Хотя, повторимся, все эти данные есть в исходном коде Гугл-Вебмастера, но копировать их оттуда Гугл запретил.
Проводим анализ
Получилось три массива данных. А дальше можно воспользоваться математическим методом поиска взаимосвязей каждого из массива данных друг с другом. Для этого идеально подойдет парный коэффициент линейной корреляции. Чем ближе он (по модулю) к 1, тем теснее связи и, соответственно, более взаимосвязаны соответствующие массивы данных. Для удобства, проведем анализ взаимосвязи «каждого с каждым», результат отобразим в таблице под названием корреляционная матрица:
| Показатель | Время загрузки | Загруженные килобайты | Количество сканированных страниц |
| Время загрузки | 1 | 0,002098 | -0,07277 |
| Загруженные килобайты | 1 | 0,693488 | |
| Количество сканированных страниц | 1 |
Кстати, величина коэффициента корреляции в программе Excel рассчитывается при помощи функции, навроде
=КОРРЕЛ(D2:D91; C2:C91)
Здесь D2:D91 и С2:С91 – первый и второй массивы данных, соответственно (диапазоны), в которых хранятся столбцы с числами.
Итак, что видим?
Два рассчитанные парные коэффициенты линейной корреляции имеют чрезвычайно малые значения, не превышающие по модулю 0,1. Это означает, что соответствующие линейные корреляционные связи являются очень слабыми, практически отсутствующими. Т.е. взаимосвязь между динамикой количества килобайт информации, загруженной роботом Google с сайта и среднего времени загрузки страницы – практически отсутствует.
Точно также отсутствует взаимосвязь между количеством просканированных в день страниц и средним временем загрузки каждой из них.
Это означает, что, по крайней мере, на данных масштабах загрузки (до 15928 кБ в день) время загрузки страниц не зависит от объема загружаемых данных. Т.е. производительность сервера, по крайней мере, на таких объемах загрузки, можно считать хорошей.
Видно также, что коэффициент корреляции между динамикой количества загруженных страниц и объемом загрузки в килобайтах составляет 0,693488, что примерно равно 0,7. Такое значение характеризует корреляционную взаимосвязь средней степени тесноты, ближе к сильной.
Этот результат очевиден. В самом деле, чем больше страниц сканируется, тем больше килобайтов загружается. Однако, так как все страницы имеют разный, неодинаковый объем и, кроме того, вероятно, каждый день сканируются РАЗНЫЕ страницы – то большие, то маленькие, то средние – поэтому зависимость не характеризуется стопроцентной теснотой (которая означала бы функциональную взаимосвязь) или близкой к тому.
Наконец, вполне возможно (см. ниже), что робот Гугла сканировал сайт, периодически меняя свою стратегию.
Если бы Googlebot сканировал каждый день ОДНИ И ТЕ ЖЕ СТРАНИЦЫ, очевидно, соответствующий коэффициент корреляции был бы близок к 1.
Уточнение
Все это, конечно, хорошо. Однако, вспомним, что анализировались линейные коэффициенты корреляции. А зависимости могут быть тесной, но НЕлинейными. При этом коэффициенты линейной корреляции могут быть, вообще говоря, любыми. Кстати, чем более сильно зависимости будут отклоняться от линейных, тем, стало быть, больше проблем Googlebot испытывает с сервером или, наоборот... (подробнее об этом – ниже).
Для более точного анализа, конечно, целесообразно бы вычислить корреляционное отношение. Однако, поступим проще и нагляднее: отобразим все на графиках.
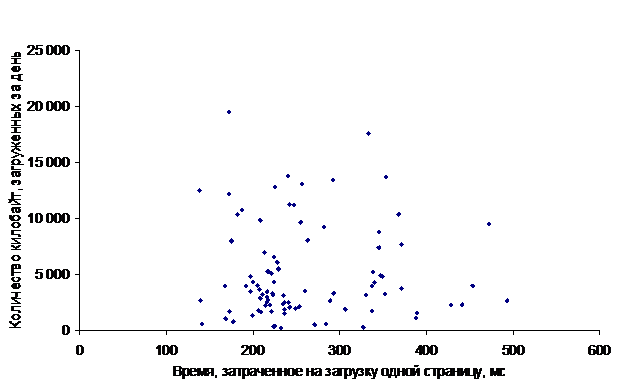
Итак, видим, что корреляционное поле зависимости количества загруженных байт от времени, потраченного на загрузку одной страницы, в самом деле, представляет собой практически равномерно разбросанную совокупность точек. Правда, можно видеть небольшое их скопление в левой его части внизу. Т.е. в большинстве случаев робот загружал страницы за 180…220 мс, что, на наш взгляд, является ОЧЕНЬ хорошим результатом.
Очень часто робот загружал в день примерно по 4000…5000 кБ информации.
Следующее корреляционное поле имеет аналогичный вид.
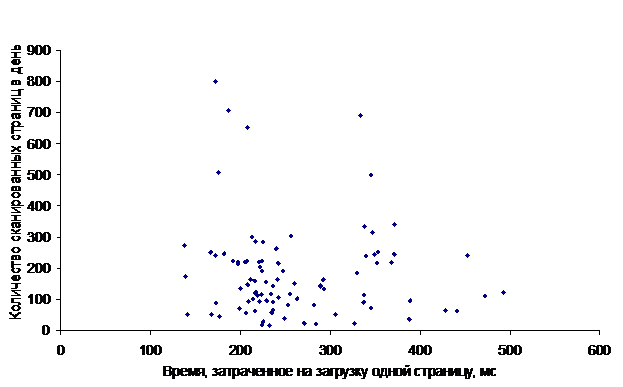
Т.е., в самом деле, никакой зависимости (ни линейной, ни нелинейной) между количеством просканированных страниц в день и временем, потраченным на загрузку, нет.
Наконец, рассмотрим третье корреляционное поле
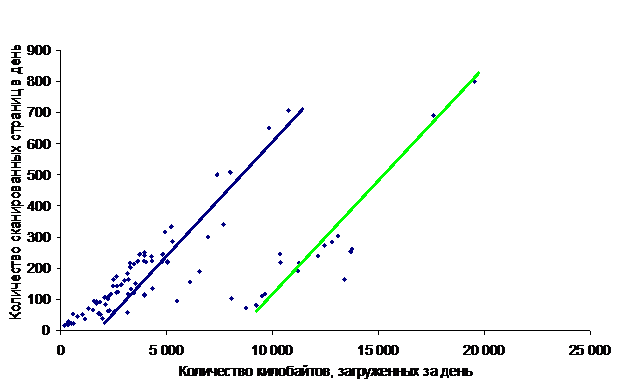
Здесь видим как бы ДВЕ характерные тенденции (тренда), поднимающиеся примерно под углом 45о вверх (отмечены на рисунке прямыми цветными линиями – синей и зеленой).
Строго говоря, синюю линию надо было нарисовать не линейной, а в виде возрастающей ветви параболы, идущей из начала координат.
Если рассчитывать коэффициент линейной корреляции не в целом для всего корреляционного поля, а для каждой из тенденций в отдельности (т.е. получится два коэффициента корреляции), то получатся более высокие значения:
Rсиней = 0,906381;
Rзеленой = 0,925294.
Таким образом, уточненный анализ позволяет по-другому взглянуть на значение коэффициента корреляции, рассчитанного для всего корреляционного поля, составившее, как мы помним, 0,693488. В самом деле, для всего корреляционного поля линейная зависимость носит весьма приближенный характер. Однако, если разделить это поле на две отдельных области (поля), получится, что каждую из них можно моделировать линейным трендом с высокой степенью точности.
Выяснилось, что в течение указанного периода робот Гугла сканировал сайт, применяя ОДНУ из ДВУХ стратегий: «маломасштабную» и «крупномасштабную», если так можно выразиться. Объемы килобайтов, загруженных за день, для этих двух стратегий различаются примерно на 7000 кБ или, ориентировочно, на 70…300%. (!)
Интересно, что же вызывает необходимость столь существенного (в разы) прироста объема загруженных килобайт в день? Почему такая необходимость возникает лишь периодически?
Характерно, что углы наклона обоих линий трендов практически идентичны. Это означает, что наблюдается прямая пропорциональность между количеством скачанных за день страниц и количеством килобайтов, загруженных за день (на уровне степени тесноты, составляющей не менее 0,9, выражаемой коэффициентом линейной корреляции).
Однако, некие факторы иногда понуждают робота при сканировании страниц реализовывать «крупномасштабную» стратегию, загружая ГОРАЗДО БОЛЬШЕ килобайт (в разы), чем в режиме «маломасштабной» стратегии. Причем, если обратить внимание на даты перехода к «крупномасштабной» стратегии, то в первых 2/3 части исследуемого периода интервал между днями ее применения составлял 1…2…3, редко – 4 дня. В последней 1/3 части периода робот почему-то довольствовался только «маломасштабной» стратегией. Несмотря на то, что материалы на сайт добавлялись в обычном режиме. Происходило также обновление уже имеющихся материалов, в частности, земельного законодательства (ибо оно в последние лет 10 в России, как известно, меняется очень часто). Поэтому приходится следить за обновлениями и вовремя вносить изменения в статьи, с учетом законодательных нововведений, но, это, повторимся, делалось в обычном режиме.
Стало быть, можно предположить нехватку ресурсов Google для полноценного сканирования интернета.
Выводы
Кратко перечислим, что выявилось в результате нашего исследования.
- При сканировании роботом объема информации до 19,528 МБ в день не наблюдается никакой зависимости между временем, затраченным на скачивание одной страницы и количеством килобайт, загруженных в день. Также не наблюдается никакой взаимосвязи между количеством сканированных страниц (вплоть до 800 в день) и временем, потраченным на загрузки одной страницы. Кроме того, максимальное время загрузки одной страницы не превысило 493 мс (такого показателя нам удалось добиться в результате оптимизации сайта, исключения ненужных функций). Это означает, что хостинг хорошо держал нагрузку в течение всего анализируемого периода времени. Т.е. хостингу НЕВАЖНО, каков будет объем загружаемой информации, если он не превышает, по крайней мере, 19,528 МБ. При этом хостинг не создавал проблем для робота Google при сканировании им сайта (кстати, этот вывод подтверждается и тем фактом, что никаких ошибок сканирования в течение этого периода не наблюдалось). Ну, а насколько этот хостинг сможет держать нагрузку и при дальнейшем возрастании объема загружаемой роботом информации, это неясно. Для этого необходимы дополнительные исследования, возможно, на другом, более объемном, сайте.
- Робот Гугл применял для сканирования данного сайта две стратегии» «крупномасштабную» и «маломасштабную», объемы скачиваемой информации при ТОМ ЖЕ количестве сканируемых страниц различались в разы (до трех раз). «Маломасштабная» применяется гораздо чаще, тогда как «крупномасштабная» - изредка. А бывают периоды, когда последняя не применяется совсем, т.е. робот ограничивается загрузкой существенно меньшего количества килобайт, при том, что число сканируемых страниц может быть тем же самым, что и при использовании «крупномасштабной» стратегии. Отсюда напрашивается следующий вывод: иногда робот сканирует страницу НЕПОЛНОСТЬЮ. Возможно, такое наблюдается даже не иногда, а часто. Вероятная причина тому – ресурсов Гугла не всегда хватает для полноценного сканирования интернета.
Кстати, последний вывод косвенно подтверждается еще и тем фактом, что, скажем, на некоторых редких языках в Google информации… раз-два и обчелся. Например, очень мало информации на башкирском языке (тогда как сайты-то башкирские, на самом деле, есть и не так уж мало).
Что дальше?
Что дальше, если рост информационных потоков продолжится? А то, что это так будет, сомневаться не приходится.
Хотя… хотя, есть и иное мнение – об этом ниже.
Если, попутно с этим, возрастет плагиат (копипаст), хотя за последний поисковые системы, вроде как, жестко наказывают, начиная с исключения плагиата из результатов поиска и кончая – баном сайта?
Один, просящийся наружу, выход – СНИЗИТЬ, существенно снизить объем растровых графических изображений, находящихся в сети. Это относится как к картинкам, так и к видео – это, наверное, даже в первую очередь. Как и что можно сделать в этой связи – фантазировать не будем. Ибо пока об этом никто не спрашивал.
Другой потенциальный выход, причем, соответствующие попытки уже делаются – ограничить в сети показ контента, который не содержит в себе так называемой «добавочной полезности». Однако это, очевидно, пока обречено на провал. Хотя бы потому, что едва ли в ближайшее время будут разработаны соответствующие компьютерные программы; ведь, если по-хорошему, здесь потребуется ни много, ни мало – искусственный интеллект.
А разного рода «словоанализаторы» (работающие… методом перебора), «алгоритмы разбивки по слогам» и т.д. – так с ними мы и будем иметь то, что уже имеем. С ними суждено быть в выдаче, отчасти, тем сайтам, которые не столько обладают полезностью, сколько будут грамотно выполнены в плане плотности и расстановки ключевых слов, заполнения заголовков h1…h6, микроразметки (интересно, кто же придумал такую ненужную вещь - ведь микроразметку может быть заспамлена точно так же, как и заголовки, например), упоминания адресов и телефонов компании на шапке сайта, наличия страниц возврата товара и гарантий, умения не попасться на покупных ссылках и прочих манипуляциях, ну и т.п.
Да и никакой компьютер, по нашему убеждению, не способен уловить стилистику и смысл, чтобы на базе этого оценить добавочную полезность. Ну, на данный момент, по крайней мере.
К тому же, нередки ведь в ТОПе поисковой выдачи и такие страницы…, которые ВООБЩЕ не содержат в себе никакой полезности, не говоря уже о добавочной, представляя собой просто несколько больших картинок (нередко, отнюдь не привлекательных) со скудными надписями на них или где-то рядом. Правда, такое оформление сейчас называется, вроде как, современным, но, строго говоря, на наш взгляд, это – современная вариация одного и того же, давно известного старого, под кратким названием ГС.
Выход у Гугла, пожалуй, пока один: серьезно взяться за борьбу с плагиатом. И вместо заявлений о «швабрах», с которыми они не намерены бегать за каждым спамером (до момента, пока на этого спамера не поступила жалоба), а САМИМ исследовать контент сети и качественно выявлять копипастеров. Да, это видится более простой, более решаемой (да и, к тому же, гораздо более полезной для интернета и для самого же Гугла) задачей, чем постоянно наращивать мощности, захлебывающиеся в потоке информации и что-то оптимизировать в своих поисковых алгоритмах (хотя это тоже необходимо, но, на наш взгляд, не первостепенно).
На наш взгляд, оптимизировать следует в настоящее время не столько поисковые алгоритмы, сколько методы и тактику взаимодействия с копипастерами. Для этого естественно, необходима ясность и четкость в таком взаимодействии.
Иное мнение
Это мнение – по поводу прогноза роста информационных потоков. На самом деле, в недалеком будущем ситуация может стать обратной. Ибо люди попросту перестанут быть способными ориентироваться в хаосе наступающей на них информации. Ладно, раньше были книги. Затем – появились радио, телевидение. Затем – интернет. Активно развивается мультимедиа.
Пока он был сложным для большинства, все было спокойно: там присутствовали только специалисты. Но, когда все упростилось, люди стали использовать интернет все чаще и чаще. Но, здесь может случиться, как с рынком сотовых телефонов, который давно уже насытился и, в целом, объем его уже сложно увеличить.
Так может статься и с информацией. Ведь человек способен обрабатывать в единицу времени, все-таки, конечный ее объем. И когда он, этот объем, станет таким, что придется перерабатывать (перебирать) мега-, а то и гига-, терабайты информации только для того, чтобы найти нужную… тогда люди (ну, подавляющее большинство, по крайней мере) могут попросту перестать ее потреблять столь усиленно, как сейчас. Довольствуясь той, что уже есть под рукой, как говорится.
Это по аналогии с нефтедобычей: когда концентрация нефти (полезности) в жиле снижается, эксплуатировать ее на каком-то этапе становится попросту невыгодно и потому рано или поздно ее закрывают. Однако, это потому, что есть другие, более насыщенные пласты и, соответственно, скважины. А если не будет больше подобных скважин? Если для добычи нефти придется выискивать остатки, доли процента там, где уже почти ничего не осталось? Тогда или добыча нефти вообще прекратится… ну, или не знаю, что еще.
Точно так же и с информацией: чем меньше будет концентрация полезной части ее, тем, в итоге, почти ВЕСЬ ее объем может стать бесполезным (по причине нерентабельности, излишней дороговизны в отборе нужной ее части). Почти весь объем, за исключением, разве что, заведомо известных и проверенных аспектов. Например, таких, как прогноз погоды.
С уважением к Вам.